ANÁLISIS DE DATOS DE DOS VARIABLES.

REPRESENTACIÓN DE DATOS DE DOS VARIABLES.
Datos de dos variables: Estos datos constan de valores diferentes que se obtienen del mismo elemento de la población.
Cada una de las dos variables puede ser naturaleza cualitativa o cuantitativa. Como resultado, los datos de dos variables pueden formarse mediante tres combinaciones de tipos de variables:
* Ambas variables son cualitativas (de atributo): Cuando los datos bivariados resultan de dos variables cualitativas (de atributo o categóricas), a menudo los datos se disponen en una tabla de clasificación o de contingencia
* Una variable es cualitativa (de atributo) y otra es cuantitativa (numérica): Cuando los datos se obtienen de una variable cuantitativa y otra cualitativa, los valores cuantitativos se consideran como muestras ajenas, cada una identificada por niveles de la variable cualitativa.
* Ambas variables son cuantitativas (numéricas):Cuando los datos son resultados de dos variables cuantitativas, los datos suelen expresarse matemáticamente como pares ordenados (X, Y), donde X es la variable de entrada (algunas veces se denomina variable independiente) y Y es la variable de salida (algunas veces se denomina variable dependiente). Se dice que los datos están ordenados porque siempre se escribe primero un valor X, y se explica que están pareados porque para cada valor X existe un valor Y correspondiente que proviene de la misma fuente.
4.1.1 Tabla de Contingencia
La tabla de contingencia es una tabla de doble entrada, donde en cada casilla figurará el número de casos o individuos que poseen un nivel de uno de los factores o características analizadas y otro nivel del otro factor analizado.
Este tema se centra en el estudio conjunto de dos variables.
Dos variables cualitativas
- Tabla de datos
- Tabla de contingencia
- Diagrama de barras
- Tabla de diferencias entre frecuencias empíricas y teóricas
- Calculo de coeficiente X2
- Cálculo del coeficiente de contingencia
Dos variables cuantitativas
- Tabla de datos conjuntos
- Diagrama de dispersión
- Cálculo de covarianza
- Cálculo del coeficiente de correlación de Pearson
Además…
Si dos variables cuantitativas están relacionadas linealmente utilizaremos la recta de
regresión.
CONCEPTOS PREVIOS
Asociación y/o relación entre dos variables: Dos variables están relacionadas entre sí
cuando ciertos valores de una de las variables se asocian con ciertos valores de la otra
variable.
ASOCIACIÓN ENTRE DOS VARIABLES CUALITATIVAS

Recordamos que la variable cualitativa era aquella que estaba medida en una escala
nominal o de clasificación (tema 1). Además pueden ser:
Dicotómicas: Cuando solo representan dos categorías
Politómicas: Cuando representan un mayor número
Cuando se dispone de los datos de dos variables cualitativas para todos los sujetos de una
muestra, se puede elaborar la Tabla de contingencia y su correspondiente diagrama de
barras (página 125). Los datos de esta tabla son las frecuencias empíricas u observadas y
se representan por (ne)
4. CORRELACIÓN ENTRE DOS VARIABLES CUANTITATIVAS
Nos presentan una tabla de datos conjuntos (página 132)
Lo primero que hacemos es elaborar el diagrama de dispersión o nube de puntos
(página 133)
Una vez realizado el diagrama y tan sólo observándolo, podemos decir que existe una
relación lineal en las variables X e Y. Es decir, a valores mayores de X corresponderán
valores mayores de Y y viceversa.
REGRESIÓN LINEAL
Cuando existe relación lineal podemos utilizar la recta de regresión para efectuar
pronósticos de los valores de una variable a partir de otra variable.
Y = a + bX
REPRESENTACIÓN DE DATOS
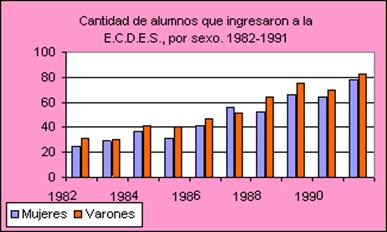
Datos de dos variables.- Estos datos constan de los valores de dos variables diferentes que se obtienen del mismo elemento de la población
Cuantitativa.- Es aquella que puede medirse numéricamente (edad, talla, altura)
Cualitativa.- son aquellas que no se miden numéricamente sino que se ordenan en categorías (sexo, nacionalidad)
Dos variables continuas
Cuando las dos resultan de dos variables continuas, los datos se disponen en una tabla de contingencia. Con (R) renglones y (C) columnas que se le conoce como una tabla R(C) y a los totales de los renglones y columnas se les denomina frecuencias marginales.
Ejemplo
Treinta estudiantes de la universidad fueron identificados y clasificados aleatoriamente según dos variables 1) genero (masculino/femenino) 2) especialización (filosofía y letras/administración/tecnología)
Las frecuencias observadas se representan en la siguiente tabla de contingencias:
ESPECIALIZACIÓN
genero | Filosofía y letras | Administración | Tecnología | Total |
Masculino | 5 | 6 | 7 | 18 |
Femenino | 6 | 4 | 2 | 12 |
Total | 11 | 10 | 9 | 30 |
FRECUENCIAS MARGINALES
De acuerdo con el ejemplo anterior la hipótesis que se planea es determinar si las opiniones son independientes de acuerdo a las materias de cada especialización o no son independientes. La llamamos hipótesis nula (Ho).
Se basa en que se adjuntan las frecuencias observadas en cada una de las seis celdas y las frecuencias que se esperan para cada celda bajo la posición de que la Ho es verdadera o no.
ANÁLISIS DESCRIPTIVO
Cuando se dispone de datos de una población, y antes de abordar análisis estadísticos más complejos, un primer paso consiste en presentar esa información de forma que ésta se pueda visualizar de una manera más sistemática y resumida. Los datos que nos interesan dependen, en cada caso, del tipo de variables que estemos manejando2.
Para variables categóricas3, como el sexo, estadio TNM, profesión, etc., se quiere conocer la frecuencia y el porcentaje del total de casos que "caen" en cada categoría. Una forma muy sencilla de representar gráficamente estos resultados es mediante diagramas de barras o diagramas de sectores. En los gráficos de sectores, también conocidos como diagramas de "tartas", se divide un círculo en tantas porciones como clases tenga la variable, de modo que a cada clase le corresponde un arco de círculo proporcional a su frecuencia absoluta o relativa. Un ejemplo se muestra en la . Como se puede observar, la información que se debe mostrar en cada sector hace referencia al número de casos dentro de cada categoría y al porcentaje del total que estos representan. Si el número de categorías es excesivamente grande, la imagen proporcionada por el gráfico de sectores no es lo suficientemente clara y por lo tanto la situación ideal es cuando hay alrededor de tres categorías. En este caso se pueden apreciar con claridad dichos subgrupos.
Los diagramas de barras son similares a los gráficos de sectores. Se representan tantas barras como categorías tiene la variable, de modo que la altura de cada una de ellas sea proporcional a la frecuencia o porcentaje de casos en cada clase . Estos mismos gráficos pueden utilizarse también para describir variables numéricas discretas que toman pocos valores (número de hijos, número de recidivas, etc.).
Para variables numéricas continuas, tales como la edad, la tensión arterial o el índice de masa corporal, el tipo de gráfico más utilizado es el histograma. Para construir un gráfico de este tipo, se divide el rango de valores de la variable en intervalos de igual amplitud, representando sobre cada intervalo un rectángulo que tiene a este segmento como base. El criterio para calcular la altura de cada rectángulo es el de mantener la proporcionalidad entre las frecuencias absolutas (o relativas) de los datos en cada intervalo y el área de los rectángulos. Como ejemplo,muestra la distribución de frecuencias de la edad de 100 pacientes, comprendida entre los 18 y 42 años. Si se divide este rango en intervalos de dos años, el primer tramo está comprendido entre los 18 y 19 años, entre los que se encuentra el 4/100=4% del total. Por lo tanto, la primera barra tendrá altura proporcional a 4. Procediendo así sucesivamente, se construye el histograma que se muestra en la . Uniendo los puntos medios del extremo superior de las barras del histograma, se obtiene una imagen que se llama polígono de frecuencias. Dicha figura pretende mostrar, de la forma más simple, en qué rangos se encuentra la mayor parte de los datos. Un ejemplo, utilizando los datos anteriores, se presenta en la
Otro modo habitual, y muy útil, de resumir una variable de tipo numérico es utilizando el concepto de percentiles, mediantediagramas de cajas. La muestra un gráfico de cajas correspondiente a los datos de la . La caja central indica el rango en el que se concentra el 50% central de los datos. Sus extremos son, por lo tanto, el 1er y 3er cuartil de la distribución. La línea central en la caja es la mediana. De este modo, si la variable es simétrica, dicha línea se encontrará en el centro de la caja. Los extremos de los "bigotes" que salen de la caja son los valores que delimitan el 95% central de los datos, aunque en ocasiones coinciden con los valores extremos de la distribución. Se suelen también representar aquellas observaciones que caen fuera de este rango (outliers o valores extremos). Esto resulta especialmente útil para comprobar, gráficamente, posibles errores en nuestros datos. En general, los diagramas de cajas resultan más apropiados para representar variables que presenten una gran desviación de la distribución normal. Como se verá más adelante, resultan además de gran ayuda cuando se dispone de datos en distintos grupos de sujetos.
Por último, y en lo que respecta a la descripción de los datos, suele ser necesario, para posteriores análisis, comprobar la normalidad de alguna de las variables numéricas de las que se dispone. Un diagrama de cajas o un histograma son gráficos sencillos que permiten comprobar, de un modo puramente visual, la simetría y el "apuntamiento" de la distribución de una variable y, por lo tanto, valorar su desviación de la normalidad. Existen otros métodos gráficos específicos para este propósito, como son los gráficos P-P o Q-Q. En los primeros, se confrontan las proporciones acumuladas de una variable con las de una distribución normal. Si la variable seleccionada coincide con la distribución de prueba, los puntos se concentran en torno a una línea recta. Los gráficos Q-Q se obtienen de modo análogo, esta vez representando los cuantiles de distribución de la variable respecto a los cuantiles de la distribución normal. En la se muestra el gráfico P-P correspondientes a los datos de la que sugiere, al igual que el correspondiente histograma y el diagrama de cajas, que la distribución de la variable se aleja de la normalidad.
COMPARACIÓN DE DOS MAS GRUPOS
Cuando se quieren comparar las observaciones tomadas en dos o más grupos de individuos una vez más el método estadístico a utilizar, así como los gráficos apropiados para visualizar esa relación, dependen del tipo de variables que estemos manejando.
Cuando se trabaja con dos variables cualitativas podemos seguir empleando gráficos de barras o de sectores. Podemos querer determinar, por ejemplo, si en una muestra dada, la frecuencia de sujetos que padecen una enfermedad coronaria es más frecuente en aquellos que tienen algún familiar con antecedentes cardiacos. A partir de dicha muestra podemos representar, como se hace en la , dos grupos de barras: uno para los sujetos con antecedentes cardiacos familiares y otro para los que no tienen este tipo de antecedentes. En cada grupo, se dibujan dos barras representando el porcentaje de pacientes que tienen o no alguna enfermedad coronaria. No se debe olvidar que cuando los tamaños de las dos poblaciones son diferentes, es conveniente utilizar las frecuencias relativas, ya que en otro caso el gráfico podría resultar engañoso.
Por otro lado, la comparación de variables continuas en dos o más grupos se realiza habitualmente en términos de su valor medio, por medio del test t de Student, análisis de la varianza o métodos no paramétricos equivalentes, y así se ha de reflejar en el tipo de gráfico utilizado. En este caso resulta muy útil un diagrama de barras de error, como en la. En él se compara el índice de masa corporal en una muestra de hombres y mujeres. Para cada grupo, se representa su valor medio, junto con su 95% intervalo de confianza. Conviene recordar que el hecho de que dichos intervalos no se solapen, no implica necesariamente que la diferencia entre ambos grupos pueda ser estadísticamente significativa, pero sí nos puede servir para valorar la magnitud de la misma. Así mismo, para visualizar este tipo de asociaciones, pueden utilizarse dos diagramas de cajas, uno para cada grupo. Estos diagramas son especialmente útiles aquí: no sólo permiten ver si existe o no diferencia entre los grupos, sino que además nos permiten comprobar la normalidad y la variabilidad de cada una de las distribuciones. No olvidemos que las hipótesis de normalidad y homocedasticidad son condiciones necesarias para aplicar algunos de los procedimientos de análisis paramétricos.
Por último, señalar que también en esta situación pueden utilizarse los ya conocidos gráficos de barras, representando aquí como altura de cada barra el valor medio de la variable de interés. Los gráficos de líneas pueden resultar también especialmente interesantes, sobre todo cuando interesa estudiar tendencias a lo largo del tiempo . No son más que una serie de puntos conectados entre sí mediante rectas, donde cada punto puede representar distintas cosas según lo que nos interese en cada momento (el valor medio de una variable, porcentaje de casos en una categoría, el valor máximo en cada grupo, etc).
RELACIÓN ENTRE VARIABLES NUMÉRICAS
Cuando lo que interesa es estudiar la relación entre dos variables continuas, el método de análisis adecuado es el estudio de la correlación. Los coeficientes de correlación (Pearson, Spearman, etc.) valoran hasta qué punto el valor de una de las variables aumenta o disminuye cuando crece el valor de la otra. Cuando se dispone de todos los datos, un modo sencillo de comprobar, gráficamente, si existe una correlación alta, es mediante diagramas de dispersión, donde se confronta, en el eje horizontal, el valor de una variable y en el eje vertical el valor de la otra. Un ejemplo sencillo de variables altamente correlacionados es la relación entre el peso y la talla de un sujeto. Partiendo de una muestra arbitraria, podemos construir el diagrama de dispersión de la
. En él puede observarse claramente como existe una relación directa entre ambas variables, y valorar hasta qué punto dicha relación puede modelizarse por la ecuación de una recta. Este tipo de gráficos son, por lo tanto, especialmente útiles en la etapa de selección de variables cuando se ajusta un modelo de regresión lineal.


.jpg)



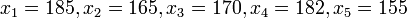

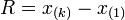

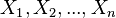 es un conjunto de datos o media muestral y
es un conjunto de datos o media muestral y  son números reales positivos, llamados "pesos" o factores de ponderación, se define la media ponderada relativa a esos pesos como:
son números reales positivos, llamados "pesos" o factores de ponderación, se define la media ponderada relativa a esos pesos como:

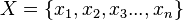

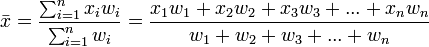
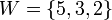
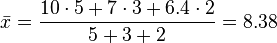
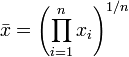
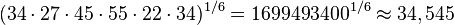

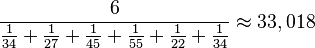




 la frecuencia absoluta del intervalo modal y
la frecuencia absoluta del intervalo modal y 
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}